
|
In this section, you will learn to carry out the GMM (Generalized Method of Moments) analysis in STATA. We will explain in detail about this in the following steps:
Let us assume, the name of the MS-Excel datasheet is "Panel-Data-Representation.xlsx" and it is located in the path "D:\data\". Then the data upload command in STATA is given by:
Once the data is uploaded in STATA, we need to define the data to be panel data. For that purpose, we need to declare the cross-section and time-series ids in the data. Then the data declaration command in STATA is given by:
Once the data is declared in STATA, you can run the GMM estimation. The basic command for running a GMM estimation in STATA is gmm. It has different options of running step-wise and iterative estimations individually. In the dataset, there are five variables (POP, EC, PT, Y, and N), and for the purpose of analysis, we can assume Y as dependent variable, POP and EC as independent variables, and PT and N as the instrumental variables. Here, we are considering POP as the exogenous variable. While choosing instruments, you should always remember this:
No. of instruments >= No. of exogenous variables. So, the command in STATA is given by:
Once we have estimated the GMM, we need to check two things:
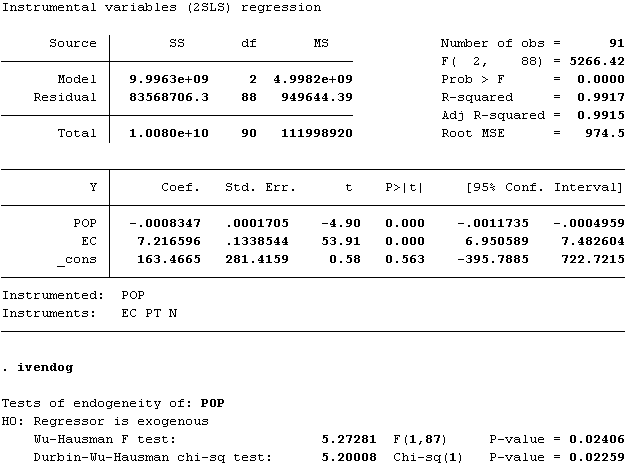
First, we will check the DWH test for checking the suitability of instruments. This test requires an instrumental variable regression on the same parameters. So, the command in STATA is given by:
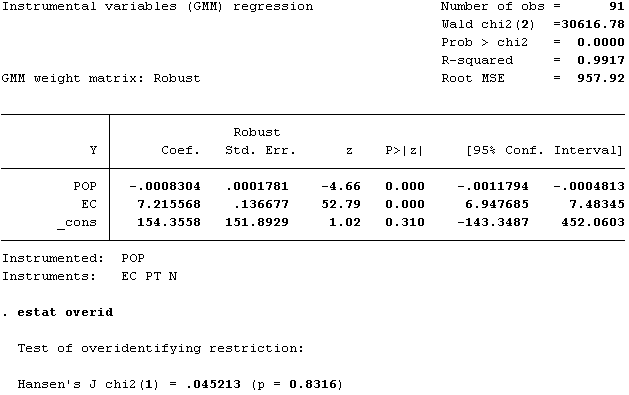
Next, we will check the Hansen's J test for checking the overidentification problem of the model. This test requires an instrumental variable regression on the same parameters using GMM estimators. So, the command in STATA is given by:
Following these steps, you can easily carry out the GMM analysis in STATA. For more information on these tests and exploring other options of GMM estimation and the diagnostic tests, please give the following commands respectively in STATA: